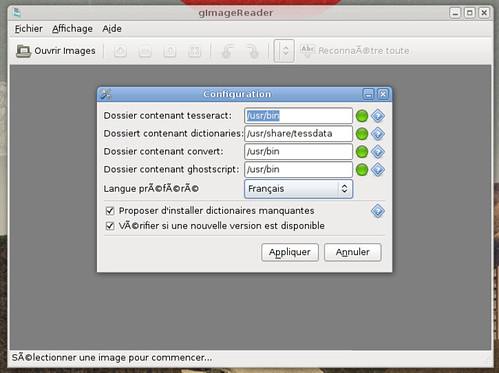
Il y a plus d’un an, je parlais du logiciel « gImageReader », bien pratique pour avoir une interface « sociale » pour l’outil d’OCR Tesseract.
Cependant, le logiciel est depuis quelques temps au point mort (la dernière modification datant d’août dernier).
Et comme je suis le mainteneur du paquet sur AUR, j’ai reçu récemment un message m’informant que le logiciel ne se lançait plus du tout.
Could not load GTK modules: /usr/lib/python2.7/site-packages/poppler.so: undefined symbol: poppler_page_render_to_pixbuf_for_printing
Après quelques recherches, le bug se trouvant lié à poppler, j’ai rapporté l’information au développeur de gImageReader pour qu’un correctif soit appliqué.
Cependant, ayant parfois besoin de récupérer des textes via l’OCR (et tesseract effectuant un travail extraordinaire dans ce domaine), j’ai décidé d’adopter le paquet xsane2tess tout en le mettant à jour.
XSane2tess, c’est un petit script qui est bien pratique, et dont un guide bien pratique se trouve sur la documentation d’ubuntu-fr.
Voici les réglages à appliquer pour utiliser xsane2tess. Les captures d’écran qui suivent sont basées sur XSane 0.998.
Première étape, après avoir installé le paquet et lancé Xsane, on va dans Préférences / Configuration / OCR.
Et dans la ligne « Commande OCR », on insère :
xsane2tess -l fra
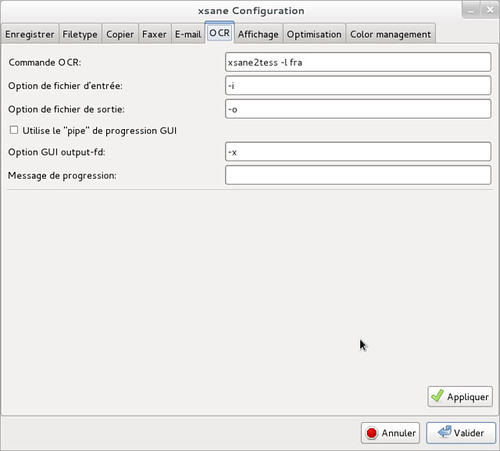
fra étant pour le français, eng pour l’anglais, deu pour l’allemand, etc… La liste des langues supportées se trouve dans /usr/share/tessdata/.
On ferme le panneau de configuration. Ensuite, pour lancer une OCR, on choisit les options suivante : pour le type, on choisit « TEXT », on prend une numérisation en « gris » et pour la résolution, on choisit 300.
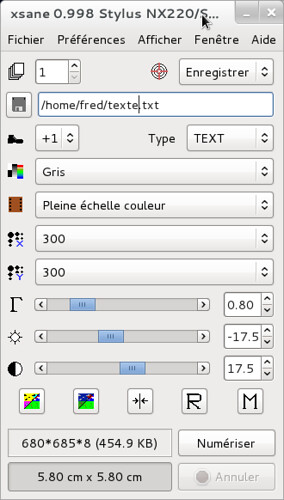
Ensuite, on acquiert l’aperçu, on sélectionne la partie à travailler, et on clique sur Numériser. Le résultat est disponible dans le nom du fichier indiqué à coté de l’icone en forme de disquette.
C’est moins « facile » qu’avec gImageReader, mais au moins, cela fonctionne encore 😉