
Il est parfois utile d’avoir un outil d’OCR. Il existe le très bon et très puissant moteur tesseract.
Cependant, toute sa puissance est exploitable uniquement en ligne de commande :(. Il y a bien un outil comme gscan2pdf, mais il demande un nombre assez important de dépendances lié à Perl.
Même si à une époque lointaine, je l’avais encensé 🙂
En faisant quelques recherches, je suis tombé sur gImageReader, un outil en python, n’ayant que peu de dépendances, en dehors de python et de tesseract :
imagemagick pycairo pygtk python-gtkspell
En m’inspirant de PKGBUILDs déjà existants pour contourner un problème de compilation, j’ai créé un paquet disponible sur AUR : gimagereader.
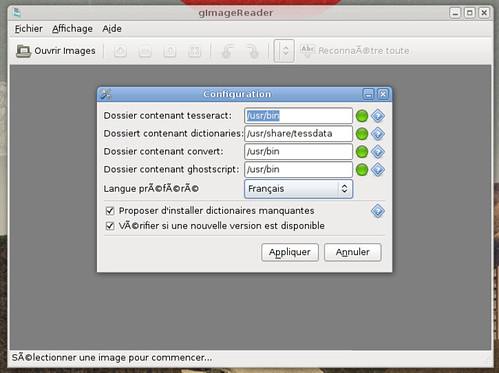
Le seul hic, c’est qu’il faut définir le chemin pour accéder aux dictionnaires de tesseract. Sur mon archlinux, ces derniers sont à l’endroit suivant :
/usr/share/tessdata
Bien que ce ne soit qu’une version 0.6, l’interaction avec le moteur de tesseract est simple et le résultat (pour peu qu’on ait une image numérisée de qualité – minimum 300 ppp) donne de très bons résultats.
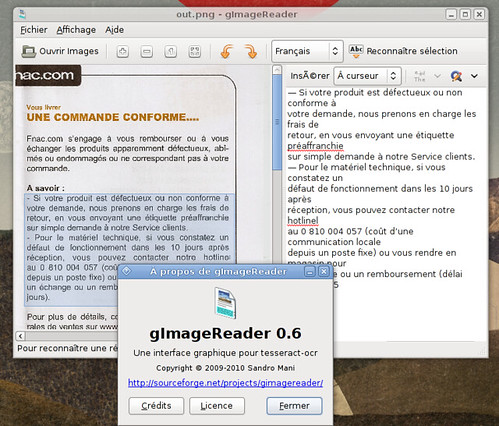
Un bug cosmétique, c’est que le logiciel ne semble pas apprécier un système en UTF-8 🙂
En tout cas, c’est un logiciel sympa, le genre d’outil dont on a besoin de temps à autres et dont on est content d’avoir sous la souris 😉
Petit message pour Devil505 : libre à toi de t’inspirer de mon PKGBUILD pour faire un Frugalbuild 😉